binwalk使用
1. binwalk、foremost、dd隐藏文件分离
Binwalk是用于搜索给定二进制镜像文件以获取嵌入的文件和代码的工具。 具体来说,它被设计用于识别嵌入固件镜像内的文件和代码。 Binwalk使用libmagic库,因此它与Unix文件实用程序创建的魔数签名兼容。 Binwalk还包括一个自定义魔数签名文件,其中包含常见的诸如压缩/存档文件,固件头,Linux内核,引导加载程序,文件系统等的固件映像中常见文件的改进魔数签名。
Binwalk常用于分析隐藏文件(CTF)
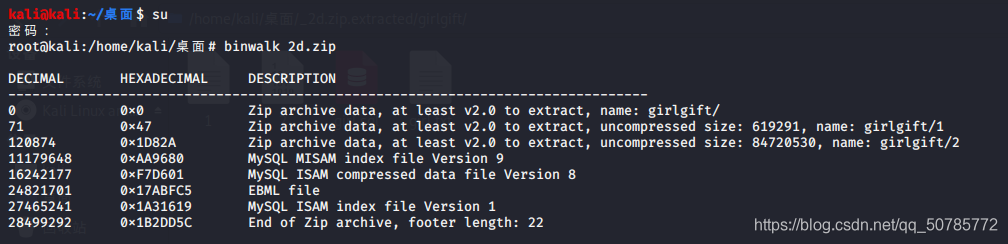
binwalk +文件名可直接扫描
通过扫描能够发现目标文件中包含的所有可识别的文件类型
binwalk -e +文件名扫描
extract自动提取已知的文件类型 ,按照定义的配置文件中的提取方法从固件中提取探测到的文件系统
1.1. binwalk参数中文说明:
1.2. 文件签名扫描选项:
-B, --signature 使用常见的文件签名扫描目标文件
-R, --raw=<str> 使用指定字节序列扫描目标文件
-A, --opcodes 使用普通可执行操作码签名扫描目标文件
-m, --magic=<file> 使用指定的特殊格式文件
-b, --dumb 禁用智能签名关键字
-I, --invalid 显示标记为无效的结果
-x, --exclude=<str> 排除与str相匹配的结果
-y, --include=<str> 只显示与str相匹配的结果
1.3. 提取选项:
-e, --extract 自动提取已知的文件类型
-D, --dd=<type:ext:cmd> 提取类型的签名<type>, 文件扩展名为 <ext>, 执行的命令 <cmd>
-M, --matryoshka 递归扫描提取文件
-d, --depth=<int> 限制-M递归的范围 (默认值: 8次)
-C, --directory=<str> 提取文件或文件夹至指定文件夹 (默认值: 当前工作文件夹)
-j, --size=<int> 限制每个提取文件的大小
-n, --count=<int> 限制提取文件的数量
-r, --rm 清除在提取过程中提取工具无法处理的零大小文件。
-z, --carve 从文件中切割数据,但是不执行提取程序
1.4. 熵分析选项:
-E, --entropy 计算文件熵
-F, --fast 使用快速但是不详细的熵分析
-J, --save 自动将由-E生成的的熵图保存为PNG文件而不是直接显示。
-Q, --nlegend 将熵图的说明省略
-N, --nplot 不生成熵图
-H, --high=<float> 设置上升边缘熵触发阈值 (默认值: 0.95)
-L, --low=<float> 设置下降边缘熵触发阈值 (默认值: 0.85)
1.5. 二进制比较选项:
-W, --hexdump 执行输入文件的十六进制转储(s)和颜色编码区分:绿色—这些字节在所有文件中都是相同的。红色-这些字节在所有文件中都是不同的。蓝色—这些字节在某些文件中是不同的。
-G, --green 只显示在所有文件中都相同的字节所在的行
-i, --red 只显示在所有文件中都不相同的字节所在的行
-U, --blue 只显示在某些文件中都不相同的字节所在的行
-w, --terse 比较所有文件,但是只显示第一个文件的16进制转储
1.6. 原始压缩选项:
-X, --deflate 用蛮力识别可能的原始压缩数据流
-Z, --lzma 扫描原始LZMA压缩流
-P, --partial 只使用常用的压缩选项搜索压缩流,速度快。
-S, --stop 在获得第一个结果后停止
1.7. 通用选项:
-l, --length=<int> 需扫描的字节数
-o, --offset=<int> 跳过文件偏移量开始扫描
-O, --base=<int>
为所有的打印结果偏移量增加一个基址
-K, --block=<int> 设置文件块大小
-g, --swap=<int> 在扫描前每n字节反转一次
-f, --log=<file> 把结果记录到文件
-c, --csv 把结果记录到CSV文件中
-t, --term 格式化输出,已使用终端窗口
-q, --quiet 禁用输出到标准输出
-v, --verbose 启用详细输出,包括目标文件MD5和扫描时间戳。
-h, --help 显示帮助信息
-a, --finclude=<str> 只扫描文件名匹配正则表达式的文件
-p, --fexclude=<str> 不扫描文件名匹配正则表达式的文件
-s, --status=<int> 在指定端口启动状态服务器
foremost在数字取证中,通过对设备备份,可以获取磁盘镜像文件。通过分析镜像文件,可以获取磁盘存在的数据。但是很多重要数据往往已被删除。这个时候,就需要还原这些文件。Kali Linux提供一款还原专用工具Foremost。该工具通过分析不同类型文件的头、尾和内部数据结构,同镜像文件的数据进行比对,以还原文件。它默认支持19种类型文件的恢复。用户还可以通过配置文件扩展支持其他文件类型。
此处只讲它的分离用途。
foremost 文件名
之后会形成一个output文件夹里面是分离出来的文件